Intel SIMD and AVX-512
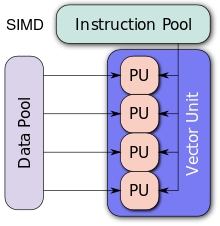
Single Instruction, Multiple Data - computers with multiple processing elements perform the same operation on multiple data points simultaneously, which exploit data level parallelism, but not concurrency - simultaneous computations, only a single process
Intel and AMD comparation
| Instruction | Num | Date | ICPU | IDate | ACPU | ADate |
|---|---|---|---|---|---|---|
| MMX | 57 | 1996-10-12 | Pentium MMX(P55C) | 1996-10-12 | K6 | 1997-4-1 |
| SSE | 70 | 1999-5-1 | Pentium III(Katmai) | 1999-5-1 | Athlon XP | 2001-10-9 |
| SSE2 | 144 | 2000-11-1 | Pentium 4(Willamette) | 2000-11-1 | Opteron | 2003-4-22 |
| SSE3 | 13 | 2004-2-1 | Pentium 4(Prescott) | 2004-2-1 | Athlon 64 | 2005-4-1 |
| SSSE3 | 16 | 2006-1-1 | Core | 2006-1-1 | Fusion(Bobcat) | 2011-1-5 |
| SSE4.1 | 47 | 2006-9-27 | Penryn | 2007-11-1 | Bulldozer | 2011-9-7 |
| SSE4.2 | 7 | 2008-11-17 | Nehalem | 2008-11-17 | Bulldozer | 2011-9-7 |
| SSE4a | 4 | 2007-11-11 | K10 | 2007-11-11 | ||
| SSE5 | 2007-8-30 | |||||
| AVX | 2008-3-1 | Sandy Bridge | 2011-1-9 | Bulldozer | 2011-9-7 | |
| AVX2 | 2011-6-13 | Haswell | 2013-4-1 | |||
| AES | 7 | 2008-3-1 | Westmere | 2010-1-7 | Bulldozer | 2011-9-7 |
| 3DNowPrefetch | 2 | 2010-8-1 | K6-2 | 1998-5-28 | ||
| 3DNow! | 21 | 1998-1-1 | K6-2 | 1998-5-28 | ||
| 3DNow!+ | 1999-6-23 | Athlon | 1999-6-23 | |||
| MmxExt | Athlon | 1999-6-23 | ||||
| 3DNow! Pro | Athlon XP | 2001-10-9 | ||||
| POPCNT | 1 | 2007-11-11 | K10 | 2007-11-11 | ||
| ABM | 1 | 2007-11-11 | K10 | 2007-11-11 | ||
| CLMUL | 5 | 2008-5-1 | Westmere | 2010-1-7 | Bulldozer | 2011-9-7 |
| F16C | 2009-5-1 | Ivy Bridge | 2012-4-1 | Bulldozer | 2011-9-7 | |
| FAM4 | 2009-5-1 | Bulldozer | 2011-9-7 | |||
| XOP | 2009-5-1 | Bulldozer | 2011-9-7 |
AVX-512
Content
Intel® AVX-512 Foundation (F)
- 512-bit vector width.
- 32 512-bit long vector registers.
- Data expand and data compress instructions.
- Ternary logic instruction.
- 8 new 64-bit long mask registers.
- Two source cross-lane permute instructions.
- Scatter instructions. — Embedded broadcast/rounding.
- Transcendental support.
Intel® AVX-512 Conflict Detection Instructions (CD)
Intel® AVX-512 Exponential and Reciprocal Instructions (ER)
Intel® AVX-512 Prefetch Instructions (PF)
Intel® AVX-512 Byte and Word Instructions (BW)
Intel® AVX-512 Double Word and Quad Word Instructions (DQ) — New QWORD and Compute and Convert Instructions.
Intel® AVX-512 Vector Length Extensions (VL)
When any 512-bit instruction is used, there is a moderate reduction in speed, and if a core uses the heaviest of these instructions in a sustained way, the core may run much slower. Furthermore, the slowdown is usually worse when more cores use these new instructions. In the worst case, you might be running at half the advertised frequency and thus your whole application could run slower.
Downclocking
-
Only happens when using 512-bits register - means we can benefit from AVX-512 instructions and features without downclocking.
-
Never get downclocking when working on 128-bit registers
-
Downclocking, when it happens, is per core and for a short time after you have used particular instructions
- Heavy instructions
- floating point operations, integer multiplication, leading-zero bits AVX-512 instructions …
- used in deep learning, numerical analysis, high performance computing, cryptograph
- Light instructions
- integer operations, logical operations, data shuffling
- text processing, fast compression routines, vectorized implementation of library routines
- Intel cores run in three model from license 0 to 2 - fastest to slowest
- L2 will happen when sustained use of heavy 512-bit instructions - one such instruction every cycle
- L1 will happen when sustained use of heavy 256-bit instructions
- using taskset and numactl to control which cores run the heavy instructions
Intel Xeon Gold 5120 processor…
mode 1 active core 9 active cores Normal 3.2 GHz 2.7 GHz AVX2 3.1 GHz 2.3 GHz AVX-512 2.9 GHz 1.6 GHz -
Notes
- Downclocking will happen in any case even if you are not using AVX-512 instructions
- Downclocking is modest when using light AVX-512 even if it across all cores
- Downclocking becomes significant when using heavy numerical work
Thoughts
- We engineers should monitor the frequency of cores and identify massive downclocking using
perf. - Massive downclocking is maybe not an important risk on machines with few cores.
- Consider isolating heavy numerical instructions work to specific threads/processes/cores, which limit the downclocking to cores and take full advantages of AVX-512. We should ensure the benefits of AVX-512 are substantial compared with non-AVX-512.
- Check that light AVX-512 gives you a greater gain compared with frequency downclocking. Even the cost is lower.
- Library, especially performance sensitive libraries, should determine whether AVX-512 is worth it and document the approach with the likely speedups from the wider instructions.
- From the compiler’s perspective, it may decide to use the AVX-512 instructions while copying structure, inline
memcpyand vectorizing loops, the decision is difficult. - We may need a tool that monitor the workload and identify when and why downclocking occurs. Meanwhile, OS or application frameworks could assign threads to specific cores.